
Fully complex-valued deep learning model for visual perception
Published in IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2023
 | Fully complex-valued deep learning model for visual perception(Oral Presentation) Aniruddh Sikdar*, Sumanth V Udupa*, Suresh Sundaram *equal contribution paper slides video |
|---|
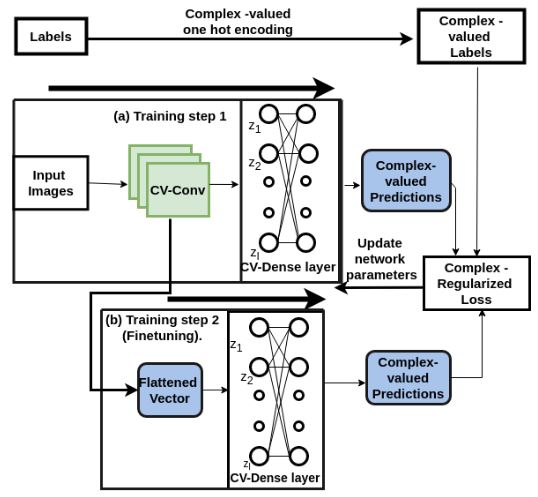
Deep learning models operating in the complex domain are used due to their rich representation capacity. However, most of these models are either restricted to the first quadrant of the complex plane or project the complex-valued data into the real domain, causing a loss of information. This paper proposes that operating entirely in the complex domain increases the overall performance of complex-valued models. A novel, fully complex-valued learning scheme is proposed to train a Fully Complex-valued Convolutional Neural Network (FC-CNN) using a newly proposed complex-valued loss function and training strategy. Benchmarked on CIFAR-10, SVHN, and CIFAR-100, FC-CNN has a 4-10% gain compared to its real-valued counterpart, with the same number of parameters. It achieves comparable performance to state-of-the-art complex-valued models on CIFAR-10 and SVHN with fewer parameters. For the CIFAR-100 dataset, it achieves state-of-the-art performance with 25% fewer parameters. FC-CNN shows better training efficiency and much faster convergence than all the other models.
Recomended Citation: Aniruddh Sikdar, Sumanth Udupa, and Suresh Sundaram. “Fully complex-valued deep learning model for visual perception.” ICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2023.